
V rámci chystané analýzy akcie Nvidia na Patreon pouštím na blog jeho jednu část veřejně. Důvody jsou dva, předně mi nepřijde, že by se na internetu válelo na toto téma příliš velké množství textu (rozhodně ne z investičního úhlu pohledu) a za druhé, nejsem programátor a jsem si velmi dobře vědom, že se zrovna v téhle problematice pohybuji někde u Mount Stupidity Duning-Krugerovy křivky, takže může obsahovat hromadu hovadin. Proto rovnou předesílám, že je text potřeba brát s rezervou a hlavně budu rád za jakékoliv komentáře a kritiku, případně faktické opravy.
Pojďme rovnou na věc. Celé téma se budu snažit podat tak, aby to pochopil úplný analfabet na programování, (což jsem ostatně taky).
Co je CUDA
To, čím se GPU liší od CPU, je způsob práce. CPU procesory (Intel a AMD procesory na architektuře x86) pracují tak, že zpracovávají v každém jádře jeden výpočet za druhým, jejich rychlost práce závisí především na frekvenci procesoru. GPU se liší v tom, že zpracovává především jednoduché operace, ale díky tomu může mít jader o několik řádů více než CPU. Kmitočet hraje roli, ale podstata výkonu u GPU je počet jader krát rychlost zpracování. Pokud bychom použili paralelu k autům, CPU je Ferrari, které sice jezdí rychle, ale vozí jen jednu krabici. GPU je tahač s návěsem.
Pokud programátor píše kód, musí nějakým způsobem do kódu implementovat, jak hardware, na kterém kód poběží, bude pracovat s programem. Tady přichází na řadu CUDA. Jedná se o programovací platformu vyvinutou Nvidií, která při implementaci do kódu programu umožňuje akcelerovat výpočty libovolného software (tzn. nejen grafiku) skrz paralelní výpočty na GPU. Jinými slovy programátor napíše software a pokud to v daném případě dává smysl, může zrychlit jeho chod tím, že vužije speciální funkce (kernely) CUDA a implementuje je do svého kódu. Tím umožní, aby na GPU Nvidie běžel program rychleji, protože grafika ho prožene všemi jádry paralelně najednou.
Dva důležité detaily. CUDA je dělaná Nvidií a tím pádem kompatibilní pouze s GPU od Nvidie. A druhý, je díky tomu vysoce optimalizovaná pro GPU Nvidie. Nvidia vyvíjí pro CUDA dokumentaci, knihovny a nástroje. Hlavní oblasti, kde se CUDA využívá jsou programy pro strojové učení, simulaci, zpracování obrazu a šifrování.
Dosavadní text není nic objevného, měl by to vědět každý, kdo si tuto akcii studoval.
CUDA je patnáct let stará (samozřejmě dostává neustále updaty) a je psaná v ne úplně uživatelsky jednoduchém jazyce (syntax dle C++) a hlavně, aby byl kód napsaný optimálně (jinými slovy aby dokázal vytěžit hardware výkon GPU na maximum), musí ji do kódu implementovat někdo, kdo velmi dobře zná hardware architekturu GPU, pro kterou ji optimalizuje. A to především architekturu SRAM paměti. Přoč vyplyne z dalšího textu.
CUDA samozřejmě není jediný způsob, jak program donutit běžet na paralelních výpočtech na GPU, ale má naprosto dominantní postavení, protože všem ostatním ujel vlak. Optimalizaci negrafického software pro grafické karty dlouhou dobu nikdo neřešil. Apple má Metal pro svoje Apple Sillicon čipy (a jsme zatím ve fázi, kdy na Metalu pořádně neběží ani grafika jako hry), Intel uvedl před několika lety One API (nikdo nepoužívá), AMD má ROCm (nikdo nepoužívá) atd. Exisuje jedna slibná vyjímka, k té se dostaneme.
Shrnul bych dosavadní text a zopakoval základní premisu: pokud programujete software a dává smysl využít paralelní výpočetní výkon GPU, tak musíte do kódu nějakým způsobem dostat příkazy pro hardware, které instruují GPU, že má výpočty provádět paralelně a jak. Nvidia s tímto přišla jako první a uvedla rozhraní CUDA, které je kompatibilní pouze s jejich grafickými čipy, je ale díky tomu i vysoce optimalizovaná pro jejich grafické čipy. Protože toto odvětví dlouhou dobu vůbec nikoho nezajímalo, drží dnes Nvidie v tomto konkrétním odvětví naprosto drtivou dominanci.
Deep Learning / Machine Learning
Tady začíná legrace, protože jdeme do poměrně slušné odborné hloubky. To co budu psát stylem pro analfabety je pro lidi, kteří se orientují v problematice velmi dobře popsané zde, za článek děkuji HappyInvestor na twitteru, který mě na něj upozornil.
Princip fungování procesoru si můžeme zjednodušit následovně.
Vezmeme část kódu, pošleme ho do mezipaměti (SRAM a DRAM), z ní ho pošleme k procesoru, ten udělá výpočet, výsledek pošle zpět do mezipaměti. Proces se opakuje s další částí kódu.
Pokud mám vyzdvihnout pointu, jedná se o to, že během procesu se buď posílají data z/na mezipaměť a nebo se provádí výpočet rovnice. Celková rychlost programu, má tím pádem dva parametry, které budou určovat, jak rychle program poběží jako celek.
Rychlost paměti a rychlost výpočtů operací.
Úzkým hrdlem je pro programy deep/machine learningu (AI) poslední roky rychlost paměti, nikoliv rychlost výpočtu. AI využívá obrovské matice, které u největších modelů přesahují velikost mezipaměti DRAM/SRAM. Navíc výpočetní výkon roste exponenciálně, rychlost paměti pouze lineárně. Vysoce optimalizované AI programy využívájí výpočty 60% času, 40% času se čeká na mezipaměť.
Psal jsem o optimalizaci kódu. V čem je pointa?
Optimalizace kódu pro paralelní výpočty omezené mezipamětí
Pokud je program bržděný mezipamětí GPU, jde zrychlit tím, že na ni nebudeme posílat data tak často. Hodně blbé přirovnání je následující. Místo abych udělal: Q: Spočítej 2+2. A: 4. Q: Vynásob 2. A: 8.; což znamená 4 interakce s mezipamětí, tak tzv. zkompilujeme kód do následujícího: Q:Spočítej (2+2)x2.
Je to hodně dementní příklad, ale pointa je správně: prostě místo abychom posílali instrukce po jedné, snažíme se sloučit několik jednoduchých instrukcí do jedné složité. Software rozhraní pro GPU opět musí umět s kompilovanými pokyny pracovat (tzn. buď si s nimi umět poradit a nebo je dekompilovat). Asi nikoho nepřekvapí, že CUDA umí přesně toto a je v tom dobrá. Nehledě na to, že kompilační pokyny v kódu se primárně staví právě na CUDA.
Pro další text je potřeba si zapamatovat, že v současném stavu je limitujícím faktorem rychlost a velikost paměti a zrychlit program lze tak, že se místo jednoduchých operací posílá do procesoru už zkompilovaný složitý výpočet.
Zpátky k AI.
Historicky měl na vývoji strojového učení dominantní postavení Google. Ten používal pro programování AI software (dlouhé roky používaný v Google Search například) vývojovou platformu Tensorflow. Jedním z hlavních charakteristik je to, že právě kompilace pokynů je už přímým předpokladem při psaní kódu. Místo aby se kód psal lineárně, je potřeba už během psaní shlukovat pokyny do složitých výpočtů. To je tak trochu náročný předpoklad na kvalitu programátora. Paralelně vedle Tensorflow využívá Google druhý vlastní aplikační rámec – JAX, který je někde napůl cesty – programuje se jednoduše lineárně, ale kompiluje si kód sám.
Paradoxně tak Google od počátku řešil svůj programovací jazyk optimálně vzhledem k omezením rychlosti paměti. Druhá výhoda je, že je pak schopen si pro vlastní software napsaný pro Tensorflow/JAX optimalizovat i vlastní procesory – TPU. Proto je taky Google reálně jediný, kdo delší dobu úspěšně používá procesory, které si designuje sám. Nevýhodou Google je to, že Tensorflow a je tak složitý, že ho dneska defacto používá už jen Google sám. Google dnes žije ve svoji vlastní bublině.
Když je Google mimo hru, co a kdo tedy dominuje programování AI? Tenhle graf ukazuje dominanci aplikačních rámců mezi deep learning studiemi – dominantní postavení má PyTorch.
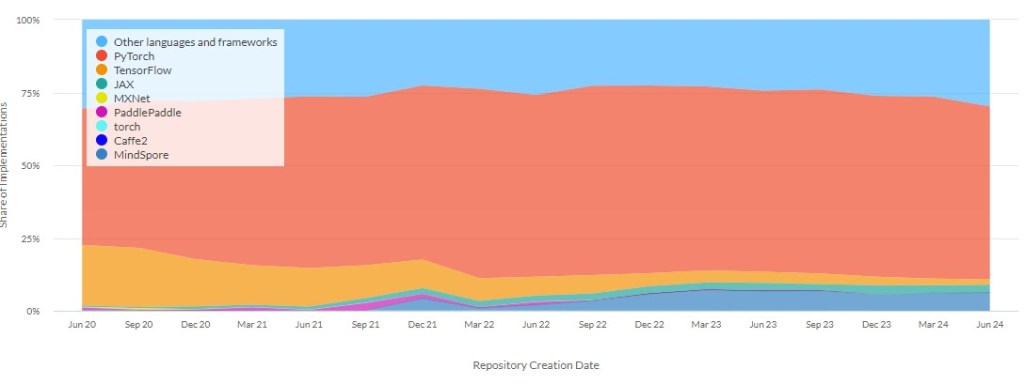
PyTorch je vývojová platforma původně vyvinutá v Meta Platforms, dnes již ale žije dlouhé roky vlastní život jako opensource software. Její hlavní výhodou je, že má stejný syntax jako programovací jazyk Python, což je jeden z nejjednodušších programovacích jazyků vůbec.
Jeho jednoduchost tkví v tom, že se v něm píše lineárně, jeden pokyn za druhým a přes procesor se zpracovává taky lineárně. Postupně a po částech. Což z předchozího textu znamená, že má značnou nevýhodu. Bez optimalizace hodně zatěžuje mezipaměť.
Aby se Pytorch programy urychlily, musí se tedy optimalizovat. Na kód je aplikována kompilace, tu ale neprovádí programátor. Pomocí nástaveb se tak PyTorch během let dostal do podobné fáze jako JAX jen z opačné strany, tzn. píše se lineárně, ale kompilace se provádí automaticky. Opět, kompilace je skvěle kompatibilní se všemi prvky CUDA, ale s ostatními platformami pro paralelizaci úplně ne.
Současný status quo má ale jeden problém (vyjma toho, že všude je nastrčená CUDA neumožňující používat cizí GPU).
Pojďme si udělat zase jednoduchou analogii, tentokrát budem stav programovacích jazyků srovnávat s běžnými cizími jazyky.
TensorFlow a JAX je taková francouzština. Určitá skupina lidí si myslí, že to je nejdůležitější jazyk na světě, ale ve skutečnosti s ním mluví ne úplně velká část populace a je složitá na naučení. Pytorch je angličtina, nejen že s ní mluví skoro všichni, ale ještě to je jednoduchý jazyk. No a CUDA, která optimalizuje využití hardware, je čínština. V ní se snažíte mluvit o jaderné fyzice.
A základní problém je v tom, že sice existují velmi chytří lidé co umí zároveň čínsky a anglicky a aspoň nějak rozumí jaderné fyzice, ale díky obrovskému boomu AI je tady hromada lidí, co umí anglicky, neumí čínsky a už vůbec nerozumí jaderné fyzice. Jinak řečeno, psát v CUDA kód do svého Pytorche neumí moc lidí. A vadí jim to. Nemluvíme o top týmech u Google, OpenAI apod. Ale o 90% toho zbytku.
OpenAI Triton
Je březen 2023, PyTorch vydává svojí verzi 2.0 a v ní je podpora OpenAI Triton. O co jde? O konkuenci CUDA, která má na starost dělat přesně to samé co dělá CUDA – paralelizaci výpočtů Pytorch kódu (místo kernelu využívá tensory) a optimalizaci paralleních výpočtů. Jeho výhodou je, že OpenAI Triton je taky postavený na syntaxu Pythonu, takže k jeho implementaci do PyTorch kódu není potřeba se učit C++. Původně sdílený článek od semianalysis je právě ze začátku roku 2023 a predikoval konec moatu CUDA.
K tomu co OpenAI Triton vůbec dělá máme úvodní článek na openai blogu, z něho je důležitá tato tabulka:
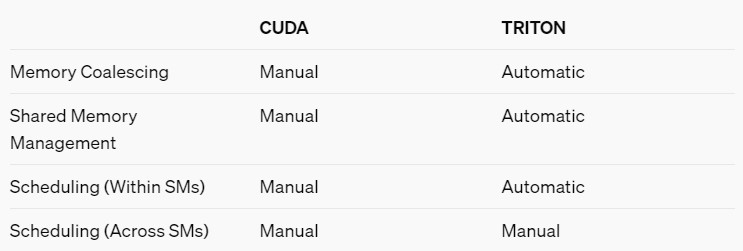
Nevýhoda složitosti CUDA programování kernelů není jen v tom, že je v syntaxu C++, ale také v tom, že musíte samy nastavit kompletní management mezipaměti a streaming multiprocesorů.
Rozdělujete jednotlivá CUDA vlákna mezi streaming multiprocesory, abyste maximalizovali paralelizaci výpočtů, dále řídíte vlákna uvnitř jednoho SM za účelem dosažení maximálního využítí výpočetní jednotky a do třetice plánujete také přepínání mezi skupinami vláken tak, abyste minimalizovali prostoje při čekání na paměť.
Oproti tomu Triton umožňuje programátorovi plánovat přidělení vláken mezi SM a zbytek už dělá Triton automatizovaně sám. Používá k tomu vlastní předtrénovaný kompilátor a výstupem z něj je Nvidia PTX kód (což je nízkoúrovňový kód pro hardware, do kterého jsou z CUDA překládány instrukce). Proto OpenAI Triton ze začátku fungoval jen na Nvidia GPU. Pointou je, že Triton se k PTX kódu pro hardware dostane bez toho, že by v průběhu procesu použil CUDA kompilátor.
To je rozhodně mnohem rychlejší a snazší, na druhou stranu velmi zjednodušený proces, ve kterém ztrácíte kontrolu nad optimalizací využití GPU. Do podrobna srovnání mezi CUDA a Tritonem řeší tento článek, je ale nad moji úroveň chápání problematiky. Jediný pro mě pochopitelný závěr je tento:
Zatimco Triton odstraňuje bariéry „vstupu do programování GPU“, protože je jednodušší pro DL programátory, tak ale nenabízí takovou flexibilitu jako CUDA a je těžké ho následně optimalizovat. To je sice v pohodě při testování nebo u malých projektů, ale ne u software, který následně stojí desítky milionů USD natrénovat.
Přidejme ještě jeden fakt. CUDA má obrovskou databázi knihoven a nástrojů, které jsou optimalizovány pro konkrétní GPU a vylepšovány poměrně velkým týmem programátorů Nvidie a mají široké uplatnění. Nejen v programování AI, ale i v jiných oborech, kde se ve velkém využívá paralelizace výpočtů. Triton byl oproti tomu navržen primárně pro deep learning a jeho penetrace do jiných oborů nebude jednoduchá. Ostatně náskok v tvorbě knihoven a nástrojů je hlavním důvodem, proč se veškerá konkurence uchýlila k opensource alternativám. Nikdo jiný totiž nemá snahu zkoušet tento náskok dotáhnout svépomocí.
Velmi dobře podporované knihovny pro CUDA jako např. cuBLAS (knihovna pro funkce lineární algebry) nebo cuDNN (funkce pro strojové účení) obsahují již optimalizované běžně používané operace a to pro každou jednotlivou verzi GPU od Nvidie (s ohledem na jejich hardwarovou architekturu). Díky tomu není práce s CUDA tak velký problém, jak původní článek na semianalysis prezentuje – je možné díky knihovnám používat optimalizaci standardních úkonů, kterou už udělal developerský team Nvidie. Ostatně i rok a půl po vydání článku a rok po veřejném releasu OpenAI Triton stále dominuje CUDA.
Závěrem
Má tedy CUDA skutečně moat? Ano má, i když už nemá monopol v rámci programovacích platforem pro paralelizaci výpočtů na GPU.
Veškerá konkurence se musela uchýlit k opensource variantám, protože není schopna dohnat náskok Nvidie in-house řešením. U opensource řešení se potkávají dva cíle – jedním je udělat rozumnou alternativu nezávislou na výrobci hardware, druhým je vytvořit programovací platformu s jednoduším syntaxem na úkor omezení funkcí. Oba dva cíle ale nutně vedou k tomu, že výsledný produkt nebude schopen využít konkrétní GPU na maximum.
Navíc se nebavíme jen o tom, že není rozumná alternativa. Když vhodná alternativa bude, musí developer dosavadní CUDA kód přepsat, jinak nepoběží na alternativních GPU. Troufám si tvrdit, že jakýkoliv pokus vytěsnit Nvidii ze svého dominantního postavení v software úrovni, bude s největší pravděpodobností trvat roky. A podmínka nutná pro tento pokus je, aby nějaký jiný výrobce přišel s čipy, které budou co se týče výkonu, alespoň lepší v poměru cena výkon. S 50% čistou marží má ale Nvidia velmi velký manévrovací prostor.
PS: nahodím sem ještě jeden užitečný link, a to na semiconductor sekci fóra pro programování grafiky. link

Napsat komentář